While reading through Brian Espinoza’s introduction to stringr, I thought I would test some speeds.
library(magrittr)
library(stringr)
library(microbenchmark)
library(data.table)
library(ggplot2)
source("~/Dropbox/Research/.Rprofile")
reps <- 1e1After loading the libraries I need, I figured I also need a big list of strings. I’ll use my list of first names compiled from various sources. I turn that into a character vector with 1119 strings.
# load the firstname database
fn_db <- fread("~/Dropbox/Research/_knowledgebase/censuslink/out/fn_links_men_5.csv") %>%
.[, list(name1)] %>%
unique() %>%
as.vector() %>%
unlist() %>%
unname()Case Changes
microbenchmark(
str_to_upper(fn_db),
toupper(fn_db),
str_to_lower(fn_db),
tolower(fn_db),
str_to_title(fn_db),
times = reps
) %>%
autoplot()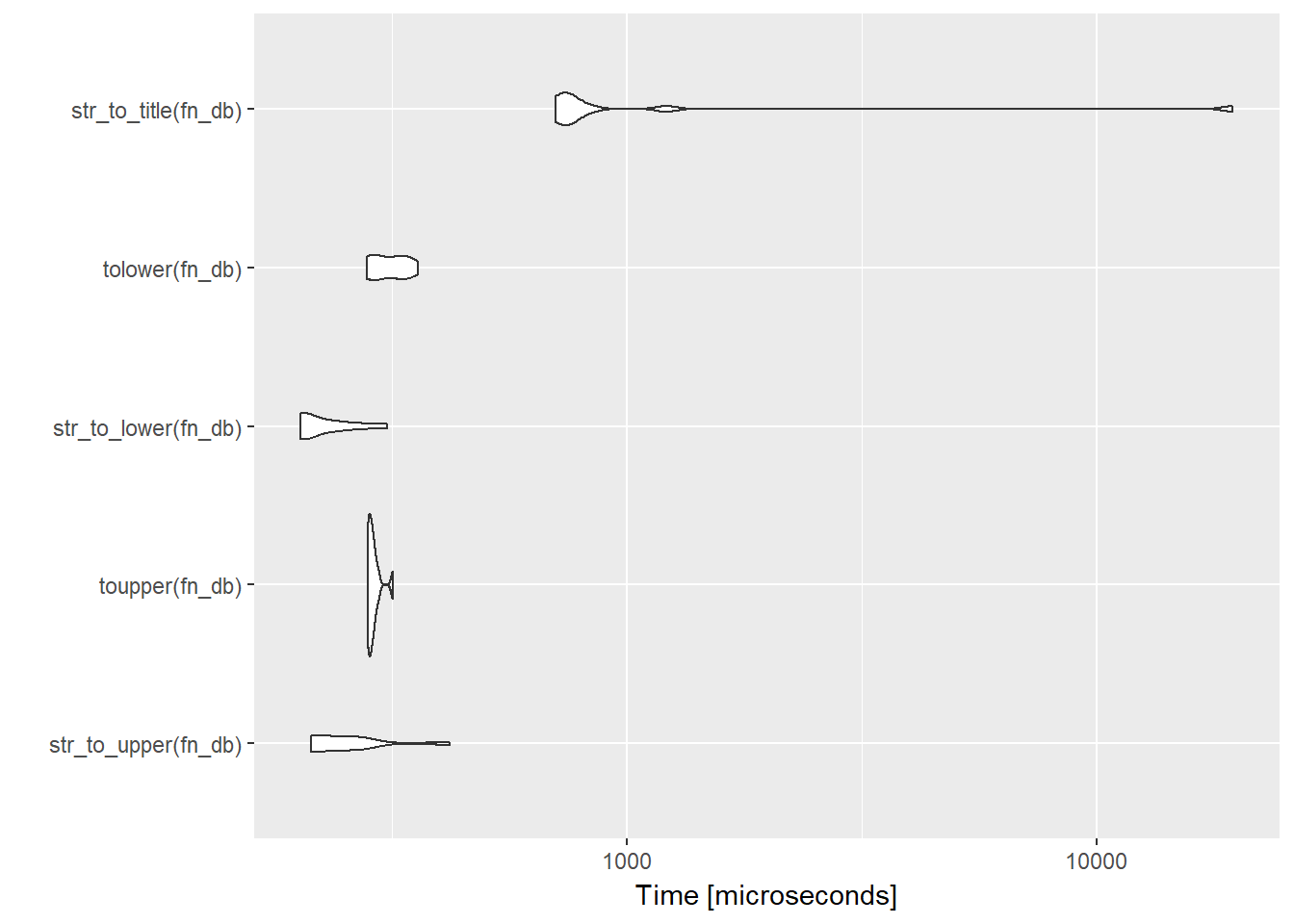
Seems like stringr is faster (though not always). str_to_title is slow but there’s nothing to compare it to in base R. (Not that I’m complaining, but the proper command in stata works just fine.)
Basic Operators
microbenchmark(
str_c(fn_db, sep = ""),
paste(fn_db, sep = ""),
paste0(fn_db),
str_length(fn_db),
nchar(fn_db),
times = reps
) %>%
autoplot()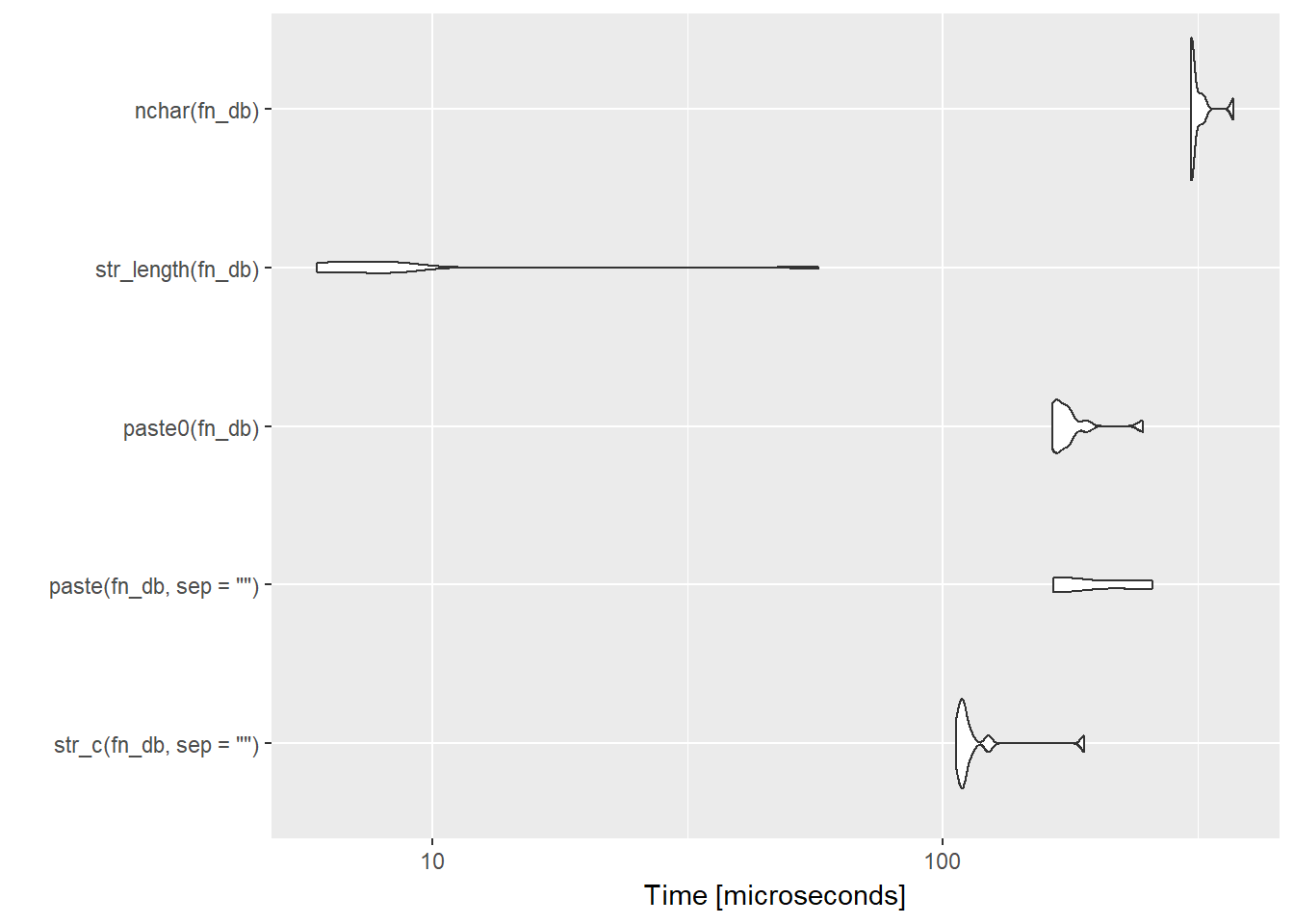
Again, win for stringr, especially when counting string lengths!
Substringing
microbenchmark(
str_sub(fn_db, start = 3),
str_sub(fn_db, start = 3, end = 5),
substr(fn_db, start = 3, stop = 5),
times = reps
) %>%
autoplot()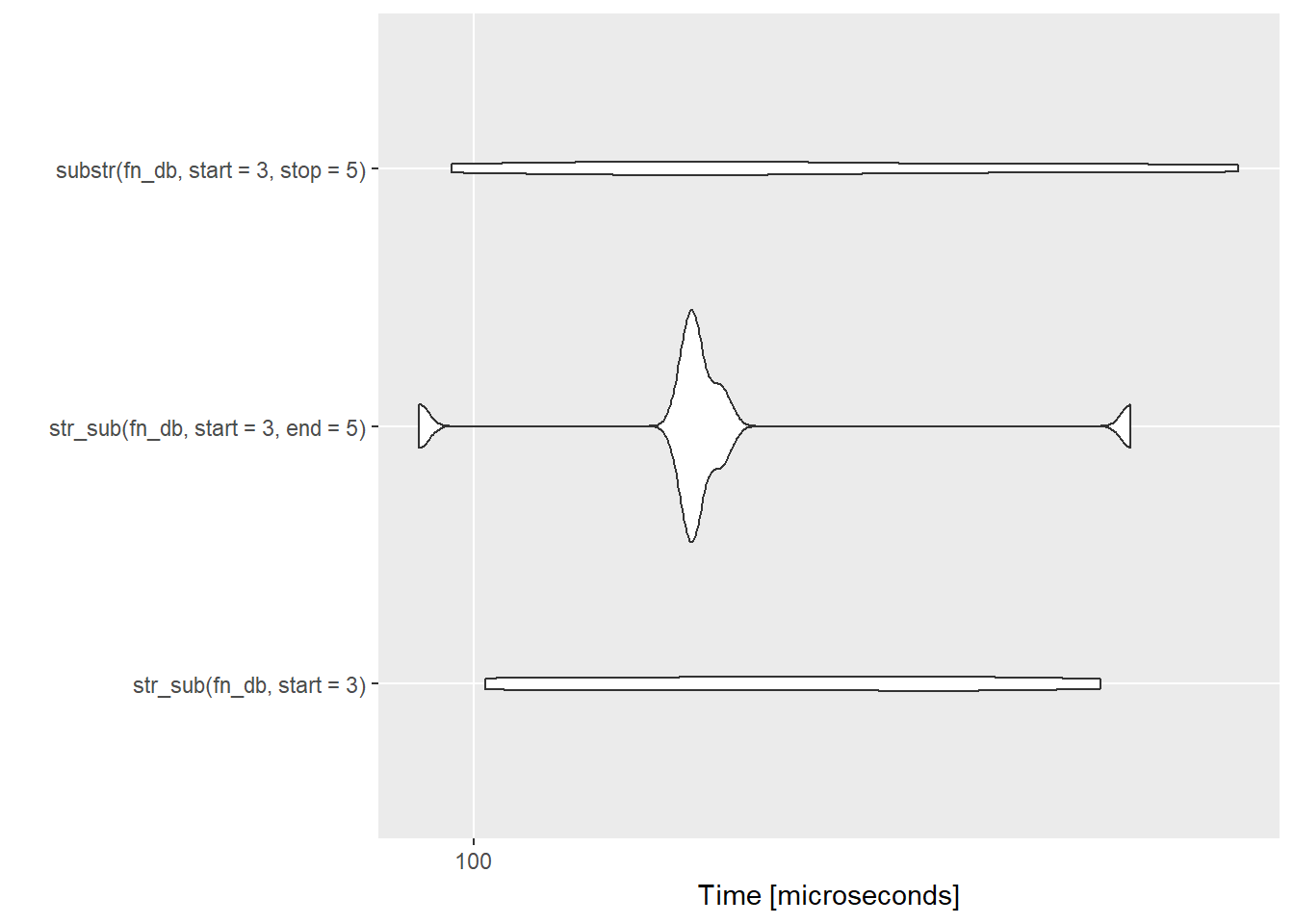
Close but stringr wins (and only str_sub works without the end or stop option, even if it is slower).
Regexing
The rest of the introduction to stringr from Brian goes through a lot of regular expression commands (str_replace, str_detect, str_extract, etc). I will have to take it on faith that these are faster than their base counterparts but they are also much easier to use and write than the base alternatives as well.